졸업프로젝트에 이용할 얼굴 인식 모델의 한국인 얼굴 인식 정확도를 높이기 위해 Facenet이 제공한 pre-trained model을 직접 수집한 한국인 연예인 얼굴 이미지로 fine tuning 하였다. 그 과정은 다음과 같다.
학교 측에서 gpu 서버를 다소 늦게 제공해주어 불가피하게 구글 colaboratory와 anaconda+jupyter notebook 조합을 넘나들며 training을 해야 했는데, 이 글에서는 구글 colab 환경에서의 학습을 중심으로 설명하겠다.
데이터 준비하기
facenet에서 제공하는 코드를 기반으로 fine tuning할 생각이라면, dataset의 구조와 형식, 설정 등을 facenet에서 이용한 dataset과 일치시켜야 한다. 이는 facenet 공식 깃허브 레포지토리의 wiki에도 잘 나와있는데, 데이터의 폴더 구조와 파일명은 다음과 같아야 한다.

모델에 넣기 전에 얼굴 이미지들은 전처리 과정을 마친 상태여야 하며, 얼굴 정렬도 되어 있어야 한다. 해당 과정을 시행하고자 할 때는 facenet에서 제공한 다음의 코드를 이용할 수 있다.
for N in {1..4}; do \
python src/align/align_dataset_mtcnn.py \
~/datasets/lfw/raw \
~/datasets/lfw/lfw_mtcnnpy_160 \
--image_size 160 \
--margin 32 \
--random_order \
--gpu_memory_fraction 0.25 \
& done
validation에 쓰이는 dataset 역시 custom dataset을 이용할 생각이라면 자신의 데이터셋에 맞는 pairs.txt를 생성해야 한다. pairs.txt란 다음과 같은 형식의 파일이다. 같은 인물의 사진 pair 300개, 서로 다른 인물의 사진 pair 300개를 1세트라고 하고 그런 세트가 10개 있다는 것을 첫 번째 줄에 나타낸다. 아래의 사진은 facenet에서 이용한 데이터셋인 lfw dataset의 pairs.txt 중 일부다.
custom data에 맞는 pairs.txt를 생성하기 위해서 아래처럼 코드를 작성하였다. 기존의 pairs.txt처럼 10세트로 구성하지 않으면 training하고 validate하는 과정에서 오류가 나서 Area Under Curve(AUC)값이 비정상적으로 도출될 수 있으니 유의하자.
import os
import random
class GeneratePairs:
"""
Generate the pairs.txt file that is used for training face classifier when calling python `src/train_softmax.py`.
Or others' python scripts that needs the file of pairs.txt.
Doc Reference: http://vis-www.cs.umass.edu/lfw/README.txt
"""
def __init__(self, data_dir, pairs_filepath, img_ext):
"""
Parameter data_dir, is your data directory.
Parameter pairs_filepath, where is the pairs.txt that belongs to.
Parameter img_ext, is the image data extension for all of your image data.
"""
self.data_dir = data_dir
self.pairs_filepath = pairs_filepath
self.img_ext = img_ext
def generate(self):
self._generate_matches_pairs()
self._generate_mismatches_pairs()
def _generate_matches_pairs(self):
"""
Generate all matches pairs
"""
folders = os.listdir(self.data_dir)
del folders[-1]
random.shuffle(folders)
for name in folders:
a = []
for file in os.listdir(self.data_dir + name):
a.append(file)
with open(self.pairs_filepath, "a") as f:
for i in range(3):
temp = random.choice(a).split("_") # This line may vary depending on how your images are named.
w = '_'.join(temp[:-1])
l = random.choice(a).split("_")[-1].lstrip("0").rstrip(self.img_ext)
r = random.choice(a).split("_")[-1].lstrip("0").rstrip(self.img_ext)
f.write(w + "\t" + l + "\t" + r + "\n")
def _generate_mismatches_pairs(self):
"""
Generate all mismatches pairs
"""
folders = os.listdir(self.data_dir)
del folders[-1]
random.shuffle(folders)
for i, name in enumerate(folders):
remaining = os.listdir(self.data_dir)
del remaining[-1]
del remaining[i] # deletes the file from the list, so that it is not chosen again
with open(self.pairs_filepath, "a") as f:
for i in range(3):
other_dir = random.choice(remaining)
file1 = random.choice(os.listdir(self.data_dir + name))
file2 = random.choice(os.listdir(self.data_dir + other_dir))
f.write(name + "\t" + file1.split("_")[-1].lstrip("0").rstrip(self.img_ext) + "\t"
+ other_dir + "\t" + file2.split("_")[-1].lstrip("0").rstrip(self.img_ext) + "\n"
)
if __name__ == '__main__':
data_dir = "/content/drive/datasets/validate/"
pairs_filepath = "/content/drive/datasets/validate/pairs2.txt"
img_ext = ".jpg"
generatePairs = GeneratePairs(data_dir, pairs_filepath, img_ext)
for _ in range(10):
generatePairs.generate()
데이터 불러오기
먼저 구글 드라이브에 데이터를 zip 형식으로 업로드 한 후, 다음 코드를 입력해 구글 드라이브를 마운트시킨다. 구글 드라이브에 google colaboratory를 설치하고 .ipynb 형식의 노트북 파일을 생성하는 방법은 여기를 참고하면 된다.
from google.colab import drive
drive.mount('./drive')
구글 드라이브가 성공적으로 마운트되었다면, 다음의 명령어를 이용해 데이터를 압축해제 해준다. colab에서 리눅스 명령어를 사용할 때는 앞에 !를 붙여줘야 한다.
!unzip -uq "파일명.zip" -d "datasets/train"
여러 개의 zip 파일을 동시에 한 폴더에 압축해제하고자 한다면 다음과 같은 코드를 이용할 수 있다.
paths = ['../../zip파일경로/어쩌구.zip', '../../zip파일경로/데이터예시.zip']
directory_to_extract_to = '../datasets/train'
import zipfile
for path_to_zip_file in paths:
with zipfile.ZipFile(path_to_zip_file, 'r') as zip_ref:
zip_ref.extractall(directory_to_extract_to)압축해제 한 파일들을 다른 폴더로 이동시키고 싶다면 다음과 같은 명령어를 사용해보자.
%cd /content/drive/datasets #특정 위치로 이동
!mv * .. #해당 위치에 있는 모든(*) 파일을 특정 폴더(..)로 이동시킴. ..는 현재 위치를 기준으로 부모 폴더를 가리킨다.
모델 불러오기
Facenet은 공식 깃허브 레포지토리에서는 두 개의 pre-trained model을 제공한다. 우리는 LFW dataset으로 validate했을 때의 accuracy가 조금이라도 더 높은, VGGFace2 dataset으로 training한 20180402-114759 모델을 이용했다. 공식 깃허브 레포지토리 > Wiki > Pre-trained model로 가면 확인할 수 있다. Model name에 걸려 있는 하이퍼링크를 이용하면 모델을 성공적으로 다운로드할 수 있다.

다운로드 후에는 구글 드라이브에 별도의 폴더를 생성한 후에 모델을 업로드해주면 된다.
혹시 깃허브를 통해 모델 파일을 업로드하고 다운로드하고자 한다면, git large file storage를 이용해야 한다. 100MB가 넘는 파일들은 파일을 push 할 때나 pull 할 때 모두 git lfs를 이용해야 한다는 걸 명심하자. 그렇지 않으면 파일이 제대로 다운되지가 않아서 오류가 난다. 웬만해서는 그냥 직접 파일을 다운받고 구글 드라이브 등에 직접 업로드하는 걸 추천한다.
GPU를 이용하여 모델 실행
우선 github와 colab 노트북을 연동하여, 앞으로 코랩에서 코드를 수정하면 깃허브에 쉽게 반영할 수 있게 한다. 구글 colab과 깃허브를 연동시키는 자세한 과정은 이곳을 참고하면 된다. 나는 Facenet 레포지토리를 fork한 후에 생성된 내 레포지토리를 구글 colab과 연결시켰다.
Facenet에서 제공하는 training code는 tensorflow2가 아닌 tensorflow 1.x 버전을 기반으로 하기 때문에 training을 하기 위해선 버전을 맞춰주는 과정이 필요하다. 처음에는 tensorflow 1.3.0을 requirements.txt에 넣고, pip install -r requirements.txt로 한 번에 다운 받았었는데 이렇게 하니 구글 colab의 gpu와 제대로 연결이 안 되었다.
그래서 찾은 방법이 이것이다. %tensorflow_version 1.x 는 구글 colab에서 제공하는 magic commad로, 이걸 이용하면 tensorflow 1.x 버전으로 변경할 수 있다. 이참에 구글 코랩에 gpu가 제대로 연결이 되어 있는지도 확인해보자. 당연히 Runtime > Change runtime type 에서 Hardware accelerator를 GPU로 바꾼 상태여야 한다!
다만, anaconda 등으로 실행환경을 바꾸게 된다면 이 커맨드는 사용할 수 없게 된다. 그때는 그냥 적당한 tensorflow 1.x 버전을 다운받아서 코드를 실행시키면 된다. 나같은 경우에는 conda에 tensorflow 1.5.0 버전을 다운받아서 코드를 돌렸다.
%tensorflow_version 1.x
import tensorflow as tf
tf.test.gpu_device_name()
위의 코드의 결과로 다음과 같이 출력되면 성공이다. 만약 gpu device 이름이 나오지 않고, ''만 출력된다면 gpu가 제대로 연결이 되지 않았다는 뜻이다.
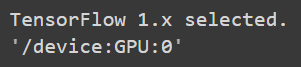
이 정도 설정을 완료하고 나면 facenet에서 제공한 코드를 이용해 모델을 실행할 수가 있게 된다. 커스텀 데이터셋 자체의 문제나 경로설정의 문제로 인해서 오류가 날 가능성이 상당히 높으니, 처음에는 우선 validate과정이 제대로 시행되는지부터 확인해보는 게 좋다. 맨 처음에는 facenet측에서 이용한 validation dataset인 lfw dataset을 다운받아서 validate_on_lfw 코드를 실행해보고, wiki에 적혀있는 accuracy값이 제대로 나오는지부터 확인하는 것을 추천한다.
!python src/validate_on_lfw.py \
../datasets/lfw \
../models/20180402-114759 \
--lfw_batch_size 100 \
--distance_metric 1 \
--use_flipped_images \
--subtract_mean \
--use_fixed_image_standardization
위의 과정이 성공적으로 이루어졌다면, custom data로도 validate해보고 제대로 실행된다는 것까지 확인을 해봐야 한다. 만약 잘 돌아간다면 training 단계로 넘어갈 수 있다. 모델을 training시킬 때는 다음과 같은 코드를 쓸 수 있다. 아래의 코드에서 로컬 환경에 맞게 조정해야 하는 부분은 각종 dir 경로와 파일 경로, gpu_memory_fraction 그리고 batch_size와 epoch_size이다.
batch_size는 하나의 batch 크기, 즉 한 번에 몇 개의 이미지들을 그룹으로 묶어서 training 시킬 건지를 정하는 것이고, epoch_size는 1 epoch에서 몇 번 batch size의 training을 반복할 것인지를 정하는 것이다. batch와 epoch, iteration 개념에 대한 자세한 설명은 여기를 참고하면 이해하기 더 수월할 것이다.
!python src/train_softmax.py \
--logs_base_dir ../logs/facenet/ \
--models_base_dir ../models/20180402-114759 \
--pretrained_model ../models/20180402-114759/model-20180402-114759.ckpt-275 \
--data_dir ../datasets/train \
--gpu_memory_fraction 0.8 \
--image_size 160 \
--batch_size 217 \
--epoch_size 122 \
--model_def models.inception_resnet_v1 \
--lfw_dir ../datasets/validate \
--optimizer ADAM \
--learning_rate -1 \
--max_nrof_epochs 300 \
--keep_probability 0.8 \
--random_crop \
--random_flip \
--use_fixed_image_standardization \
--learning_rate_schedule_file data/learning_rate_schedule_classifier_vggface2.txt \
--weight_decay 5e-4 \
--embedding_size 512 \
--lfw_distance_metric 1 \
--lfw_use_flipped_images \
--lfw_subtract_mean \
--lfw_pairs data/pairs.txt \
--validation_set_split_ratio 0.05 \
--validate_every_n_epochs 5 \
--prelogits_norm_loss_factor 5e-4
epoch는 전체 트레이닝 셋이 모델을 통과한 횟수이기 때문에 batch_size * epoch_size 즉, 한 epoch에 들어가는 이미지들의 개수는 전체 이미지 개수와 동일하거나 적어도 비슷해야 한다. 위의 코드를 우선 실행시켜보면 다음과 같이 이미지 개수가 출력되니 그 결과를 참고해 batch_size와 epoch_size를 설정하면 된다. 나는 training set의 example 수에 해당하는 값을 약수 공약수 계산기에 넣어서 적당한 size들을 골랐다. batch size를 너무 크게 설정하면 에러가 날 수 있으니 유의하자.
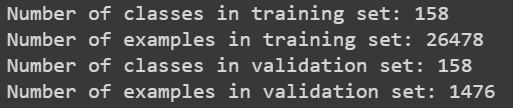
fine-tuning 시행하기
training이 되는 것까지 확인했다면 드디어 fine tuning을 시도해볼 수 있다. fine tuning을 수월하게 하기 위해선 모델의 layer 구조를 파악해야 하는데, 이때 이용할 수 있는 게 tensorboard다. 레이어 구조를 확인하는 작업을 별도로 하지 않고 마냥 fine-tuining을 하다가는 갈피를 잃은 채로 기계적으로 training을 하게 될 수도 있기에 초반부터 layer 구조를 잘 파악하고 어떤 layer를 학습시킬지 잘 선택하는 걸 추천한다.
tensorboard를 성공적으로 연결시키면 모델 구조를 시각화해서 확인할 수 있으나.. 몇 번을 시도해도 tensorboard 결과가 제대로 얻어지지 않아서 나는 그냥 training code 속에서 이용되는 tf.trainable_variables() 함수를 이용하여 확인하였다.
pre-trained model을 training시켰던 dataset과 우리의 custom dataset의 크기가 차이가 많이 나서 최대한 영향을 적게 주면서 fine-tuning하고자 말단의 layer 2개만 제외하고 기존의 layer들은 pre-trained model 파일에서 변수값을 restore해오도록 하였다. 그 부분의 코드는 다음과 같다.
# Create a saver
set_A_vars = [v for v in tf.trainable_variables() if v.name.startswith('InceptionResnetV1')]
saver_set_A = tf.train.Saver(set_A_vars, max_to_keep=3)
saver_set_A_and_B = tf.train.Saver(tf.trainable_variables(), max_to_keep=3)
.....
with sess.as_default():
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
if pretrained_model:
print('Restoring pretrained model: %s' % pretrained_model)
saver_set_A.restore(sess, pretrained_model)
....
# Save variables and the metagraph if it doesn't exist already
save_variables_and_metagraph(sess, saver_set_A_and_B, summary_writer, model_dir, subdir, epoch)
이제는 training 결과를 확인하면서 이것저것 조정해보고.. 바꿔보면서 결과를 또 기다리면 된다. 나는 false acceptance rate, 즉 far_rate값과 learning_rate을 계속 조정하면서 training 시켰다.
Validation 값들 이해하기
facenet에서 제공하는 코드를 이용해 training을 하면 매 epoch가 끝날 때마다 accuracy와 validation rate값이 출력되는 것을 확인할 수 있다. 이 척도는 모델 자체의 성능을 파악하고 training의 방향을 잡아가는 것과 직접적인 연관이 있기에, 이 값들이 정확히 어떤 것을 의미하는지 설명해보고자 한다.

우선 Accuracy 값은, 전체 중에 맞은 것의 개수. 즉, (true positive + true negative)/size의 값이다. 이때 사용하는 threshold값은 accuracy값이 가장 높게 나오는 threshold를 계산하여 선정하기 때문에, accuracy가 높아도 false positive rate이 상당히 높게 나올 수 있다.
이를 보완하기 위한 척도가 validation rate값인데, 이는 far target 값과 일치하는 far값을 가지는 threshold값을 보간법으로 구하여 계산한 true positive rate(tp/(tp+fn))값이다. 이때 far은 false acceptance rate, 즉 false positive rate(fp/(fp+tn))이다.
far target값은 초기에 1e-3값으로 설정되어 있으며, 프로젝트 특성과 accuracy, validation rate 결과값에 따라 조금씩 조정해가며 training 시키면 된다.
마지막으로, 원활하게 모델 training을 시키고 싶다면 구글 colab pro를 꼭 결제하는 걸 추천한다. 사비로 결제하기가 꺼려져서 미루고 미뤘지만 퍽하면 세션이 끊기고 기본으로 제공되는 gpu 사용량을 넘어서서 제대로 모델학습을 시킬 수가 없었다. 따라서 구글 colab pro는 꼭 결제하는 것을 추천한다.
'CS > 기계학습(ML)' 카테고리의 다른 글
| 기존의 얼굴 인식 모델들(FaceNet, VGG-Face)을 이용해 한국인 얼굴 인식해보기 (1) | 2021.11.24 |
|---|---|
| Face Detection과 Face Recognition의 차이 (0) | 2021.11.23 |